kubernetes crash course
| Code | |
|---|---|
| Created | |
| Importance | very important |
| Language | |
| Materials | https://www.youtube.com/watch?v=X48VuDVv0do |
| Reviewed | |
| context | DevOpskubernetes |
| source | YT |
table of content
intro
orchestration tool for containers
cons
- high availablity or no down time
- scalability
- disaster recovery
k8s components
pod
- smallest unit of k8s, is an abstraction over container
- usually 1 app per pod
- each pod has its own ip
- new ip address on re-creation
service
- permanent ip address can be attached to each pod
- lifecycle of pod and service are not connected
- if pod dies service and ip stay
external service
internal service
ingress
forward requests to services
configmap:
- external conf of your app
- dont put credentials ⚠️
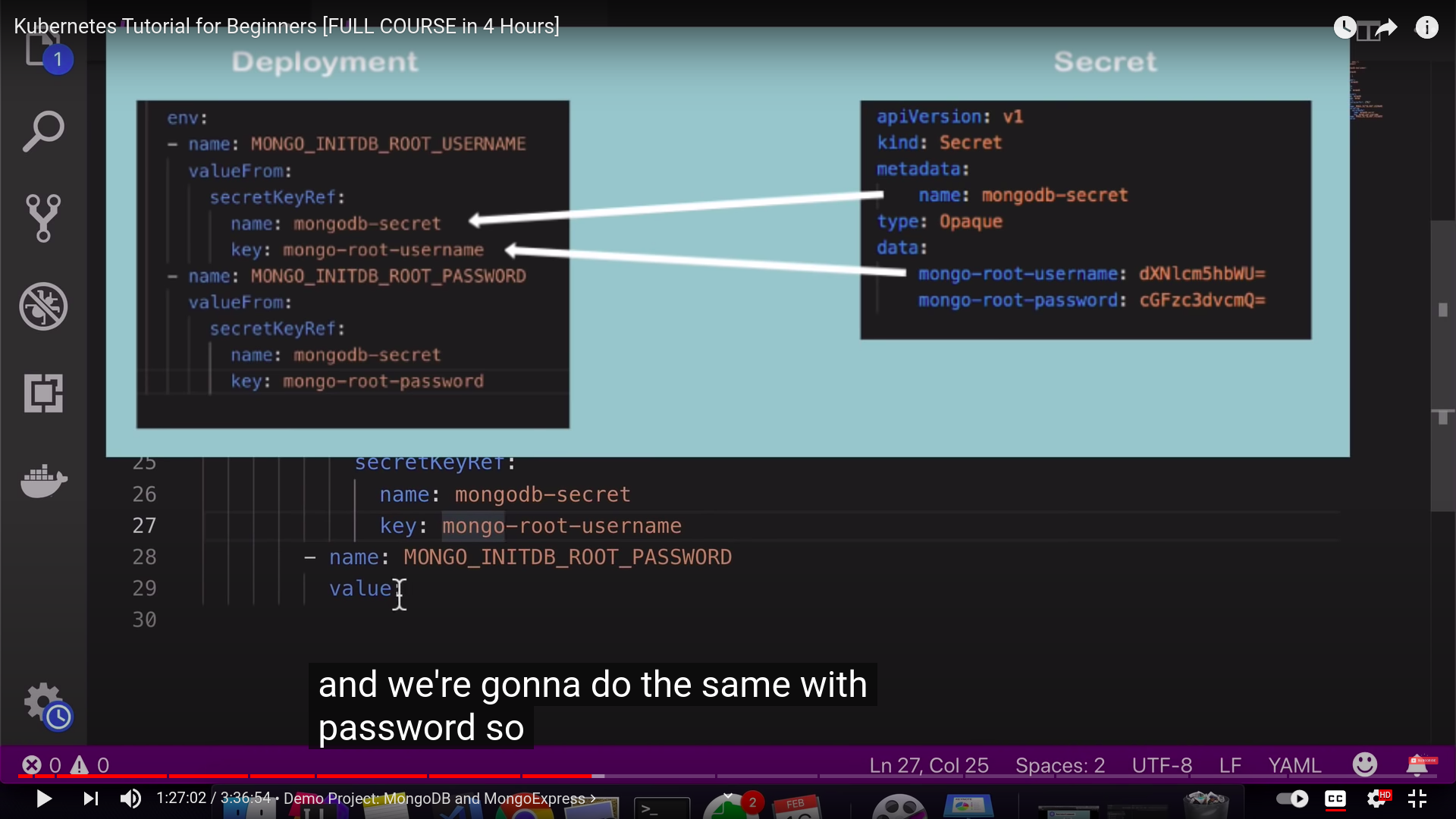
secret:
- like configmap but used for secrets
- used to store secret data
- encoded in base64
- ⚠️ ‼️ built-in securtiy mechanism is not enabled by default
- used data from
secret:orconfigmap:as env variables or properties file
volumes
we can attach either local or remote (outside k8s cluster)
k8s doesn't manage data persistence you have to manage it explicitly using volumes
replica
- connected to the same service, another node but same service
- service is also load balancer
Deployment:
- you wont create replica for pod but you will define blueprint for the pod which contains how many replica
statefulSet:
for statefull apps
- mysql
- elastic search
- mongo DB
- etc.
- deploying
statefulSetnot easy
K8S Architecture
worker machine
- node - or server-
- each node has multiple pods
- worker do the actual work
3 processes must be installed on each node
kubelet
- process of k8s itself
- interact with node and pods
- take the config and run the pod inside and assign resources for pods
container runtime
- docker for example
kubeproxy
- foward the requests
- has intellegient forward logic to make it good performance
how to interact with cluster
master node
master processes
1 - api server
- cluster gateway
- acts as a gateway for authentication
- only 1 entrypoint to the cluster
slide
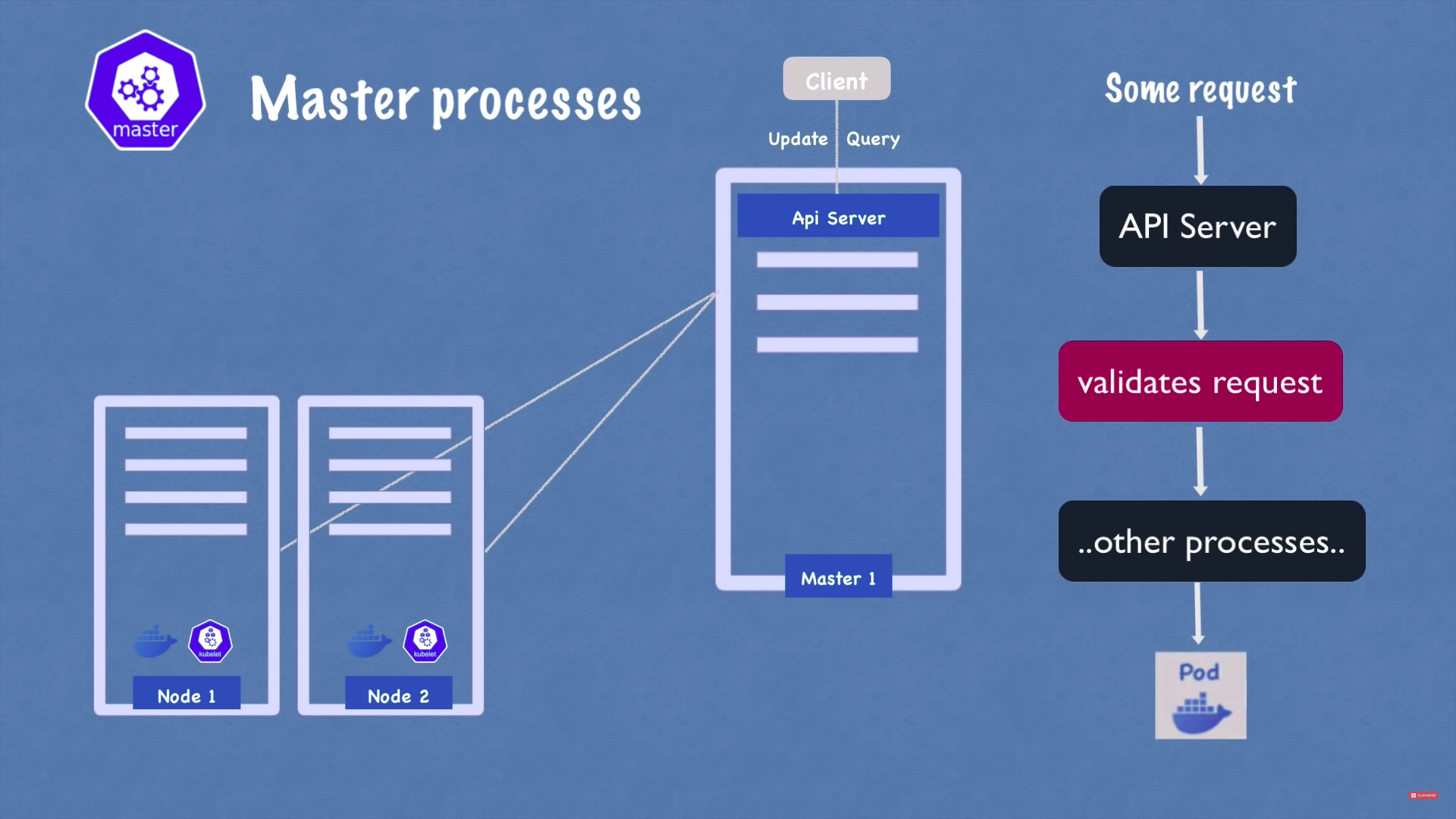
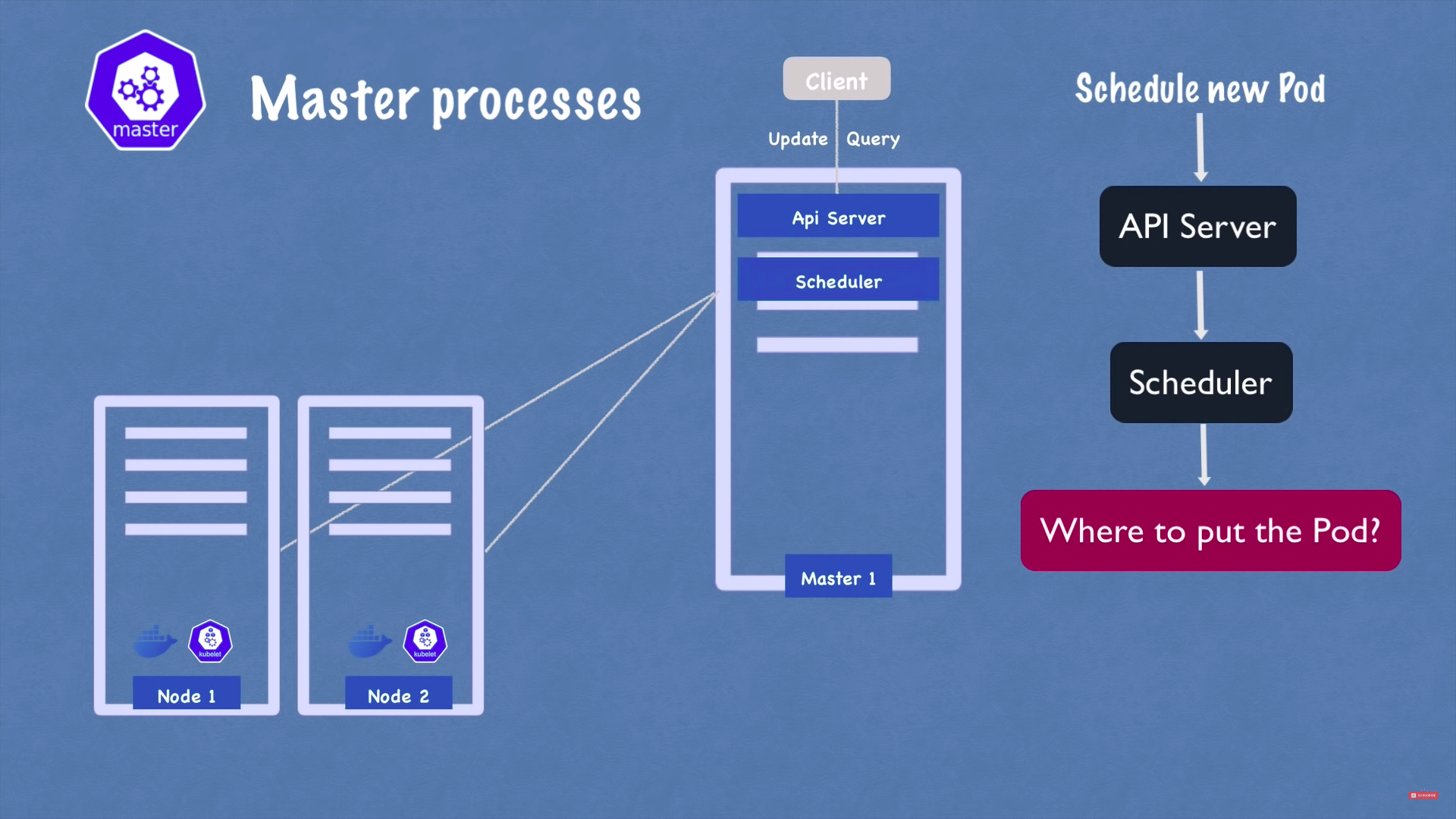
2 - scheduler
slide
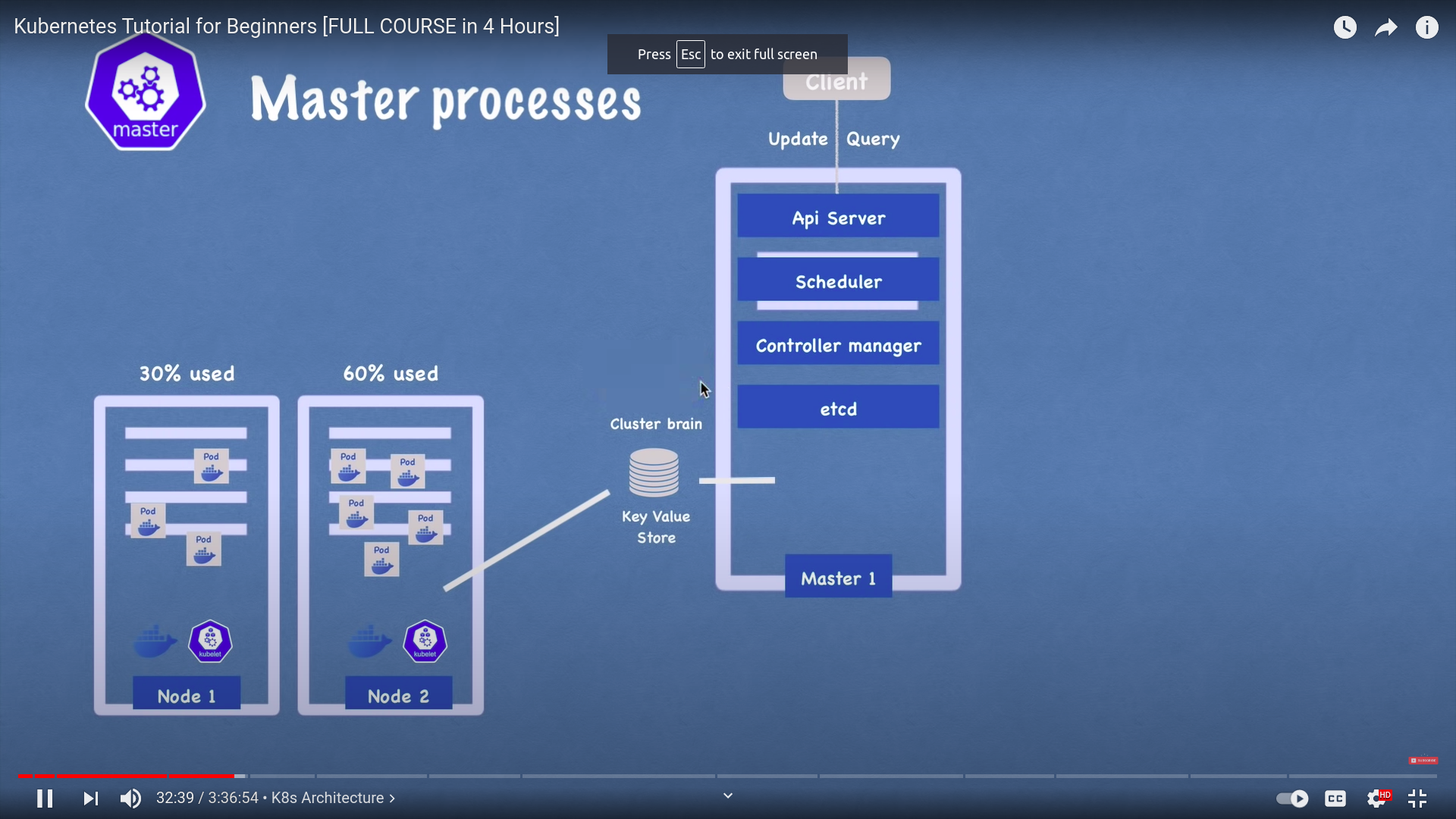
3 - controller manager
4 - etcd(cluster brain)
application data not stored in etcd
slide
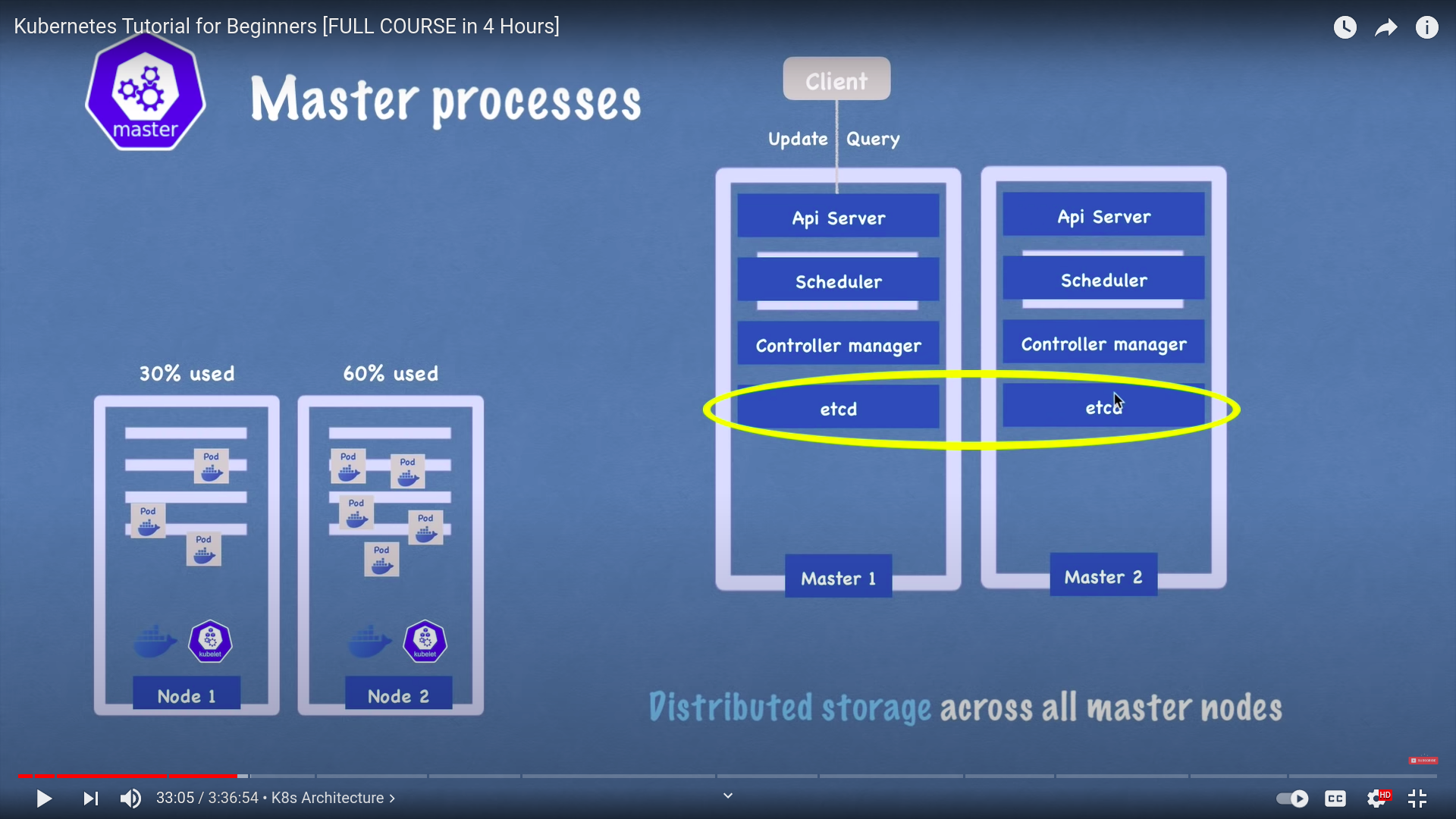
we can multiple master nodes
- which have its master processes
- api server is load balanced
- etcd is distributed storage accross all master nodes
slide
example cluster
- master nodes resources is important but it need less resources bec it has less work load
MiniKube
- a one node cluster
- used to test locally
- for testing purposes
- creates a virtual box on your machine
- node runs in that vbox
- we have master node and working node on the same machine
kubectl
we need to interact with api Server either using UI, api or CLI ⇒ kubectl and its the most powerful one
- used in minikube and cloud clusters as well
minikube installation on ubuntu
kubectl basic commands
create
- pods are the smallest unit of k8s
- using
kubectlyou won't createpodsbutdeploymentwhich is an abstraction over pods
kubectl create deployment NAME --image=image [--dry-run] [options]configure kubectl with zsh
example
what happens when we run
kubectl create deployment nginx-depl --image=nginx
there's a middle layer between deployment and pod which is replicaset which creates the replicas for the pod
deployment has such as the blueprint for creating pod and its replica
the previous example is minimalistic providing name and image only and the rest is set by default
in real life yopu won't need to deal with replicaset but deployment
- if we run
> $ k get pods
> nginx-depl-5c8bf76b5b-mp6hz
> $ k get replicaset
>nginx-depl-5c8bf76b5b
- in the previous example we have only one replica for the pod
- we can see that the pod gets its id by prefix
nameof deployment thenhashfromreplicathenhashforpod
layers of abstractions
- deployment manages a replicaset
- a replicaset manages all replicas of that pod
- pod is an abstraction of a container
- container
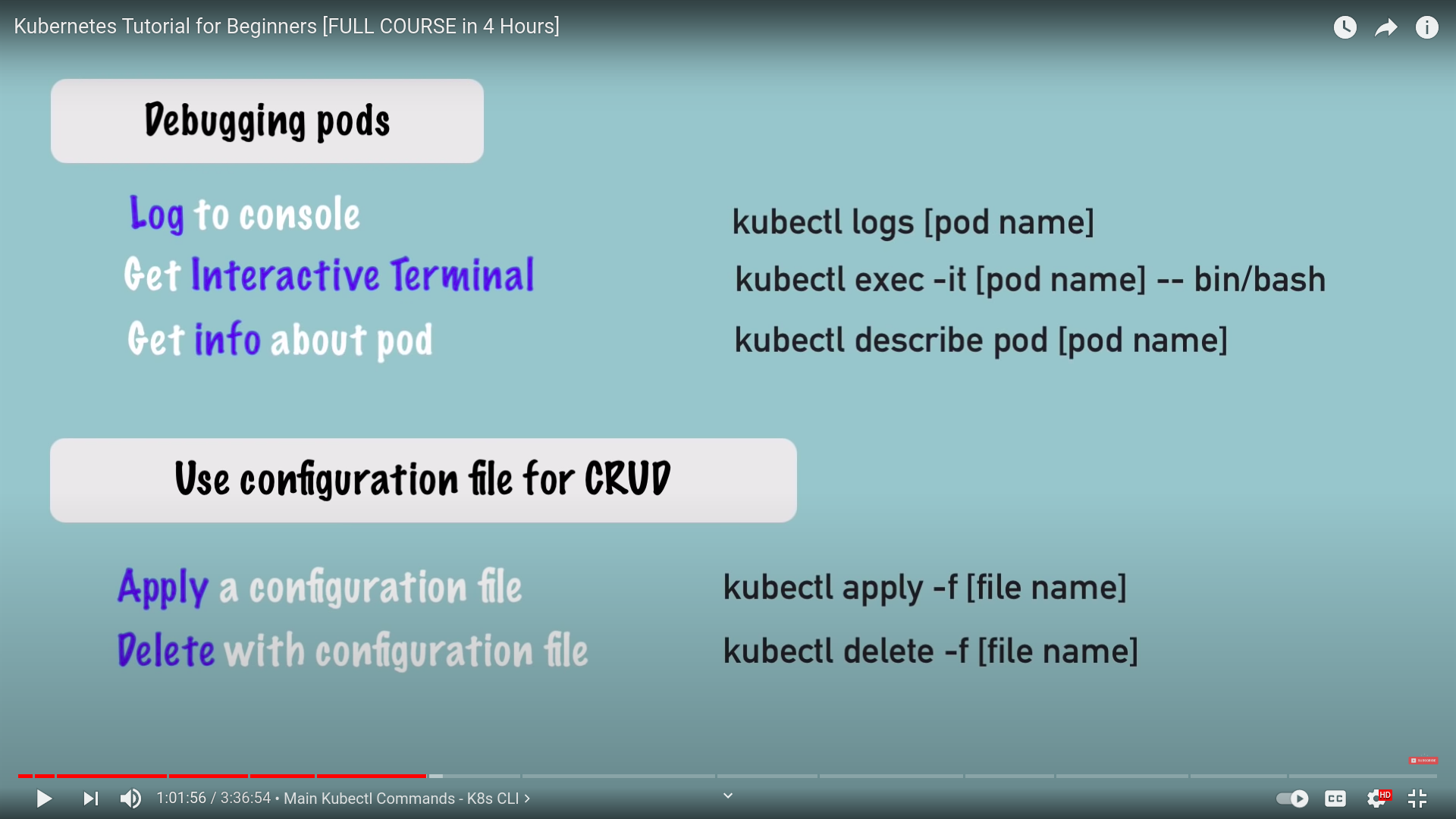
debugging pods
kubectl excec -it [pod name] --bin/bashdelete deployment and apply config file
kubectl delete deployment [name]we deal with files for config
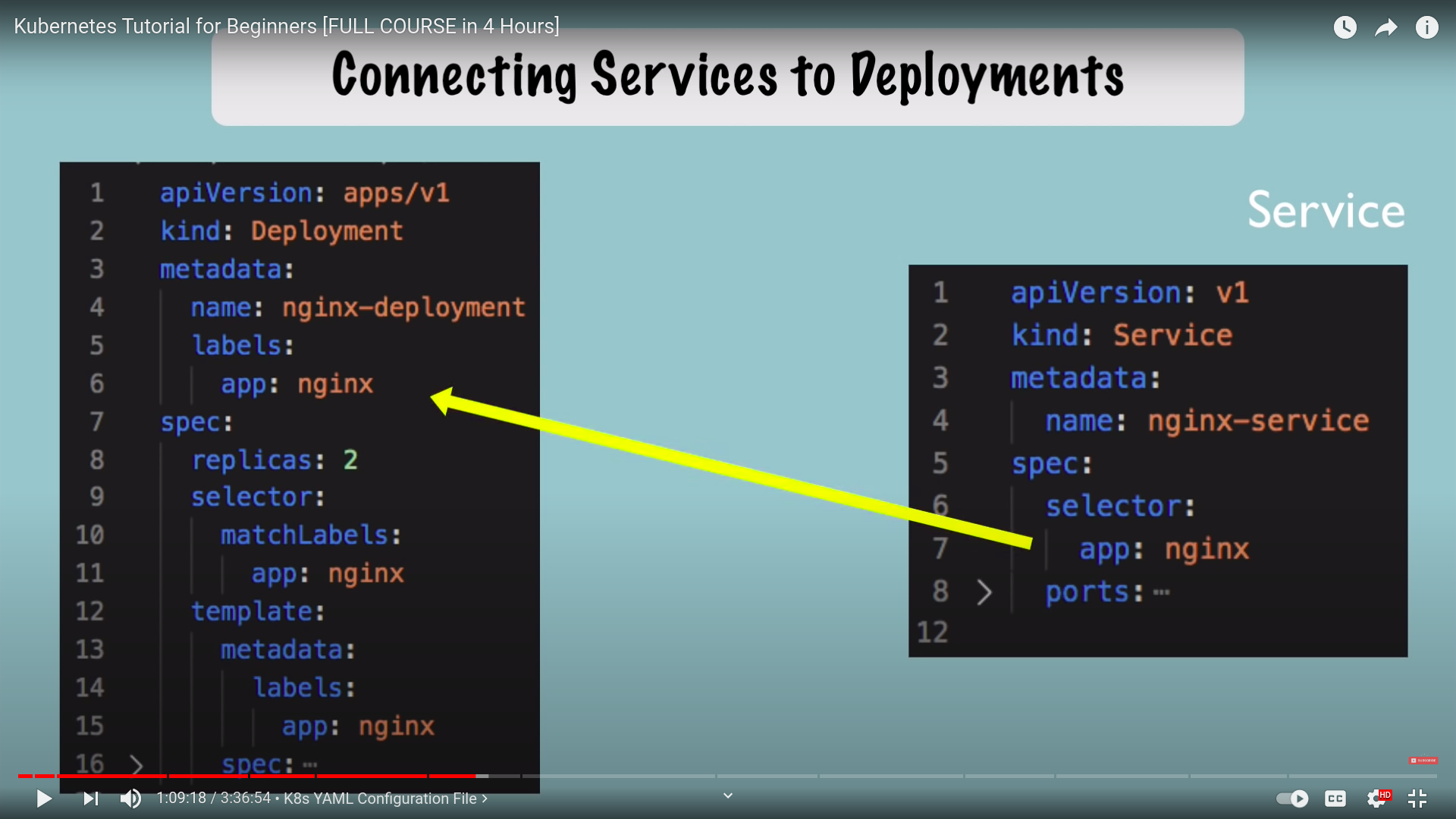
kubectl apply -f [filename]- here's a code snippet for config file for nginx
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec: # specs of deployment
selector:
matchLabels:
app: nginx
replicas: 1 # tells deployment to run 1 pods matching the template
template:
metadata:
labels:
app: nginx
spec: # specs for the pod
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80- run this by running
kubectl apply -f [filename]
summary

YAML config files
- each configuration has 3 parts
- Metadata
- specification
- attributes of
specare specific to the kind
- attributes of
- status
- automatically generated and added by k8s
- Desired vs. actual
- if it's not equal k8s decides that there's smth needs to be fixed
- k8s updates status continously
- where does k8sget this status data ?
etcdthe cluster brain
etcdholds at anytime current status of any k8s component
- is indentation strict
- store the config with your code or their own repo
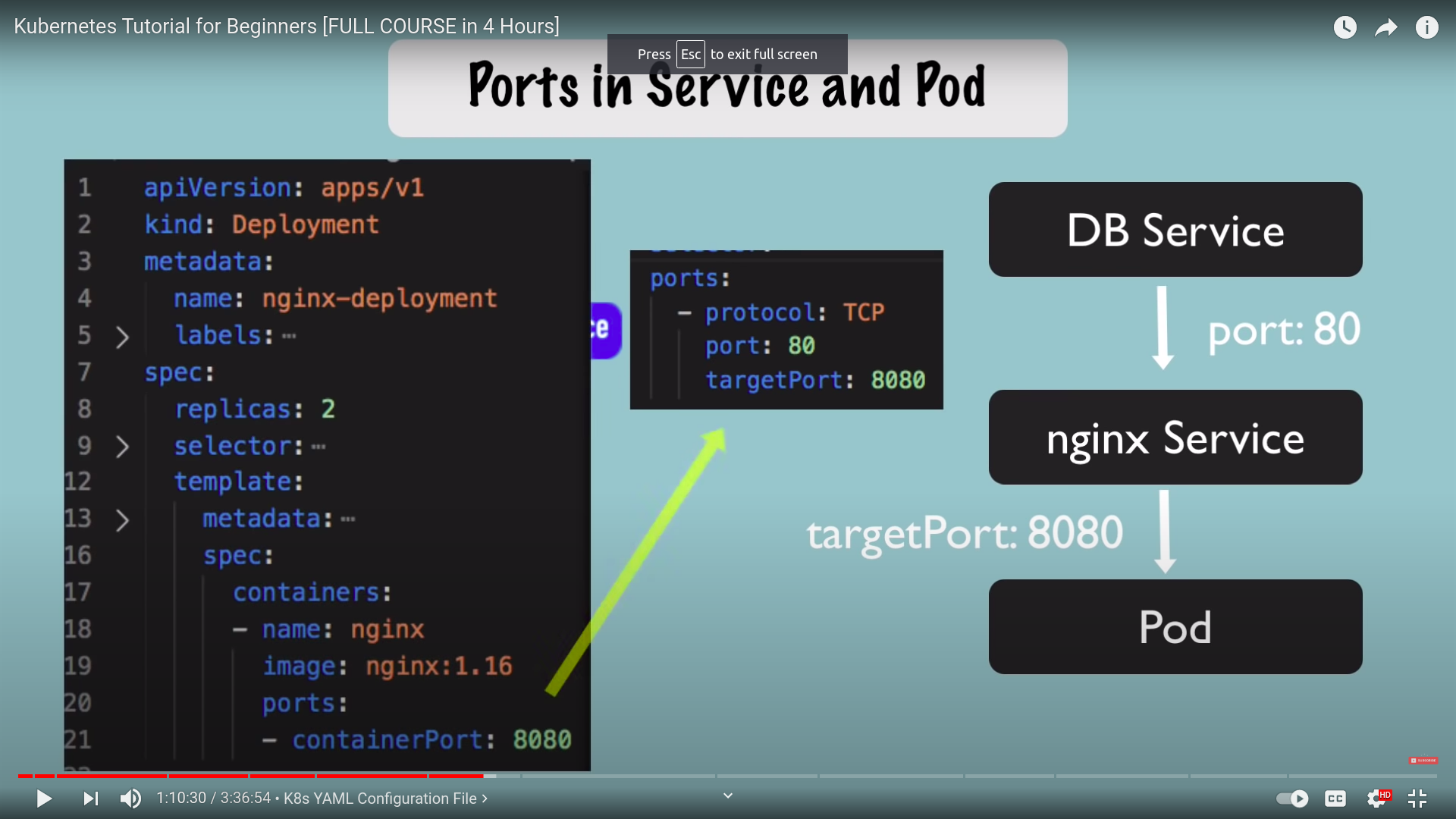
- which port to access the service
- which
targetportto forward requests to - configured in pod - and should match container port
we have types for secrets
- must probably we use the default one with is Opaque
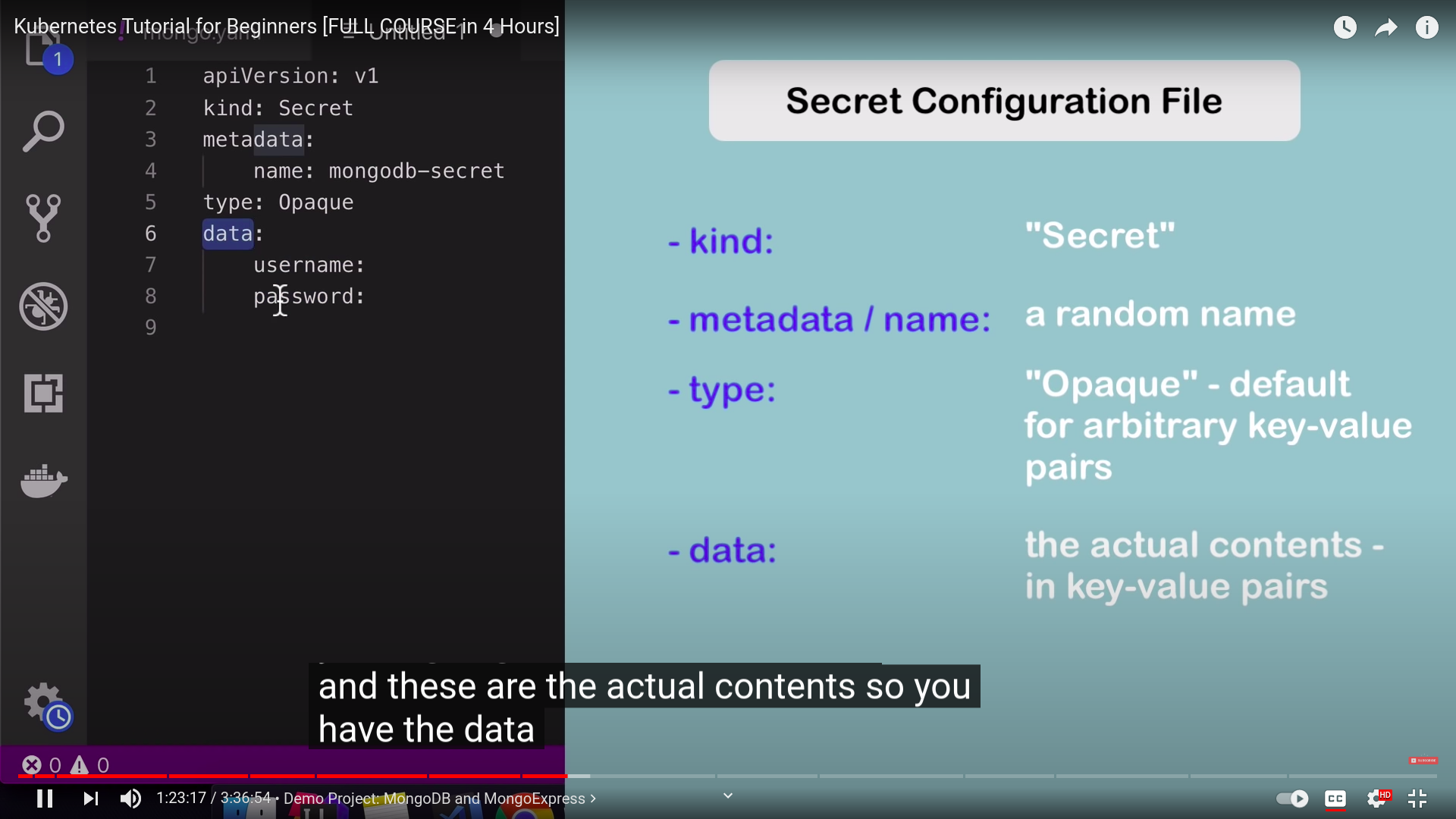
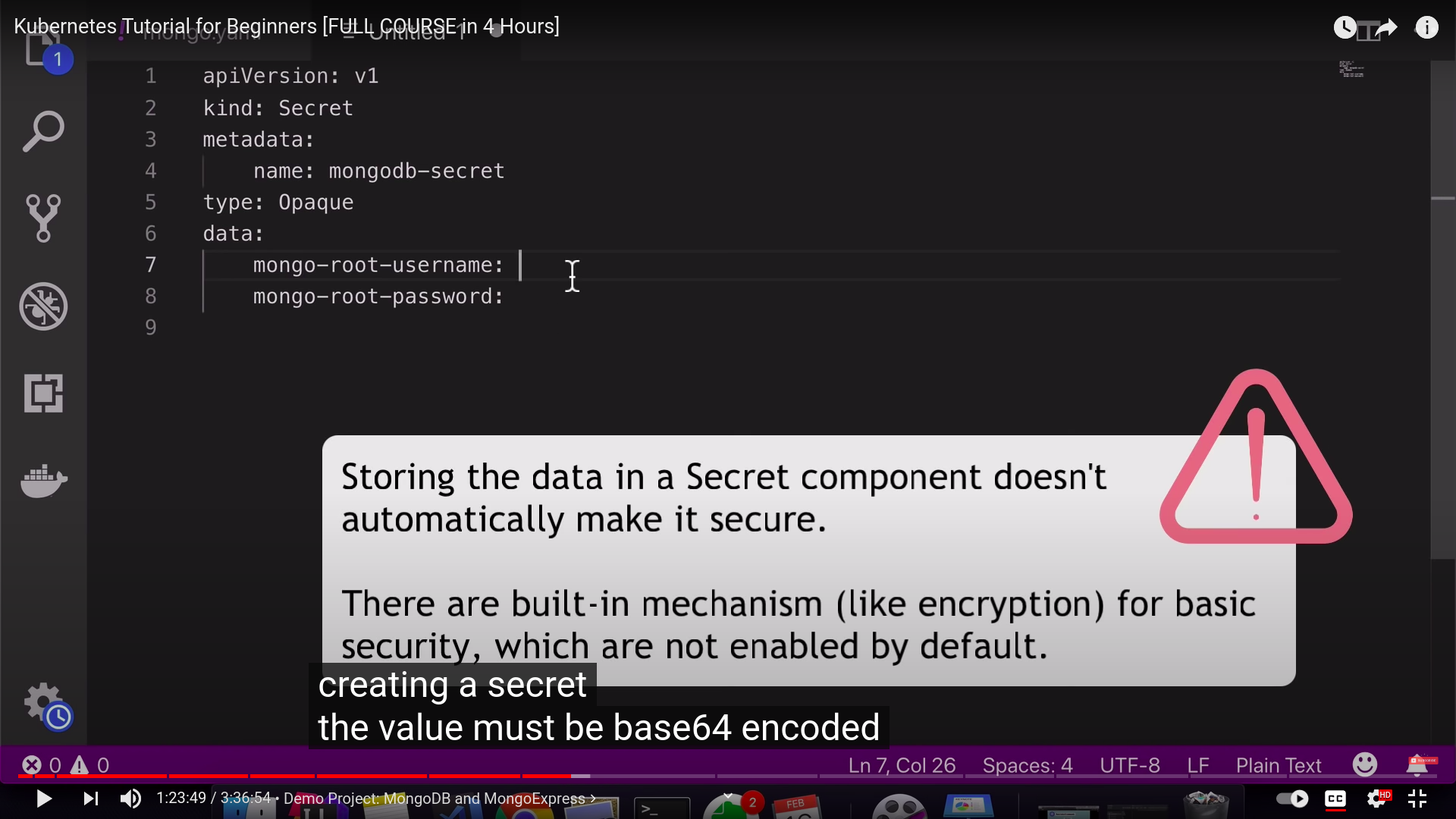
- we must create secret before deployment if the deployment refers to it
organizing components using namespaces
- organize resouces in namespaces
- virtual cluster inside cluster
- 4 namespaces by default
$ kubectl get namespaces > default Active 41h kube-node-lease Active 41h kube-public Active 41h kube-system Active 41h- kubesystem
- don't createor modify in
kube-system
- system processes
- master and kubectl processes
- don't createor modify in
- kube-public
- publically accessable data
- configmap that contains cluster information accessable even without authentication
- kube-node-lease
- heart beats of the nodes
- each node has associated lease object in namespace
- determines the availablity of a nodes
- default namespace
- you're gonna be using to create the resouces at the beginning if you haven't created one
- kubesystem
create namespace
from command line
kubectl create namespace [namespace-name]add namespace config to file
apiVersion: v1
kind: ConfigMap
metadata:
name: mongodb-configmap
namespace: my-namespace
data:
database_url: mongodb-servicewhy use namespace ?
- structure your components
- avoid conflicts between teams
- share services between differenet envs
- acces and resouce limits on namespace level
characterestics
- you can't access most of resouces from another namespaces
- each NS should create its own
ConfigMap,secret
- each NS should create its own
- access service from another namespaces
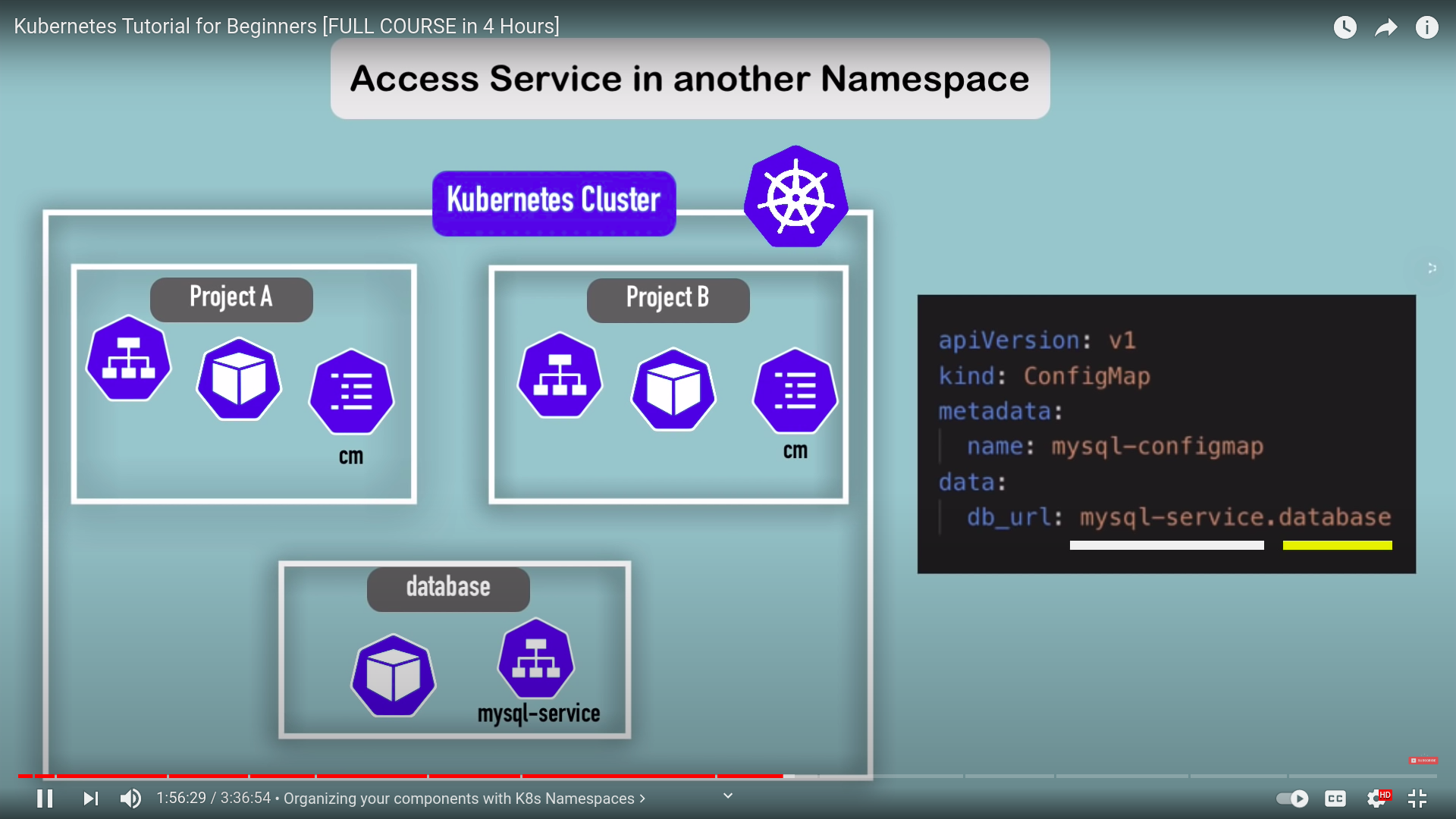
- components which can't live in namespaces
- live globally in cluster
- can't isolate them
- example :
volumenode
- you can list components that not bound to namespace or bound
kubectl api-resouces --namespace=[false | true]
create components in namespace
- if you don't apply namepsace in config it will be in the default namespace
- can be done using
--namespace=or in file inmetadata
- you can change active namespace using tool
kubens
K8S ingress
minikube config
minikube addons enable ingress this command automatically starts k8s Nginx implementation of Ingress controller
HELM
package manager for k8s
templating engine
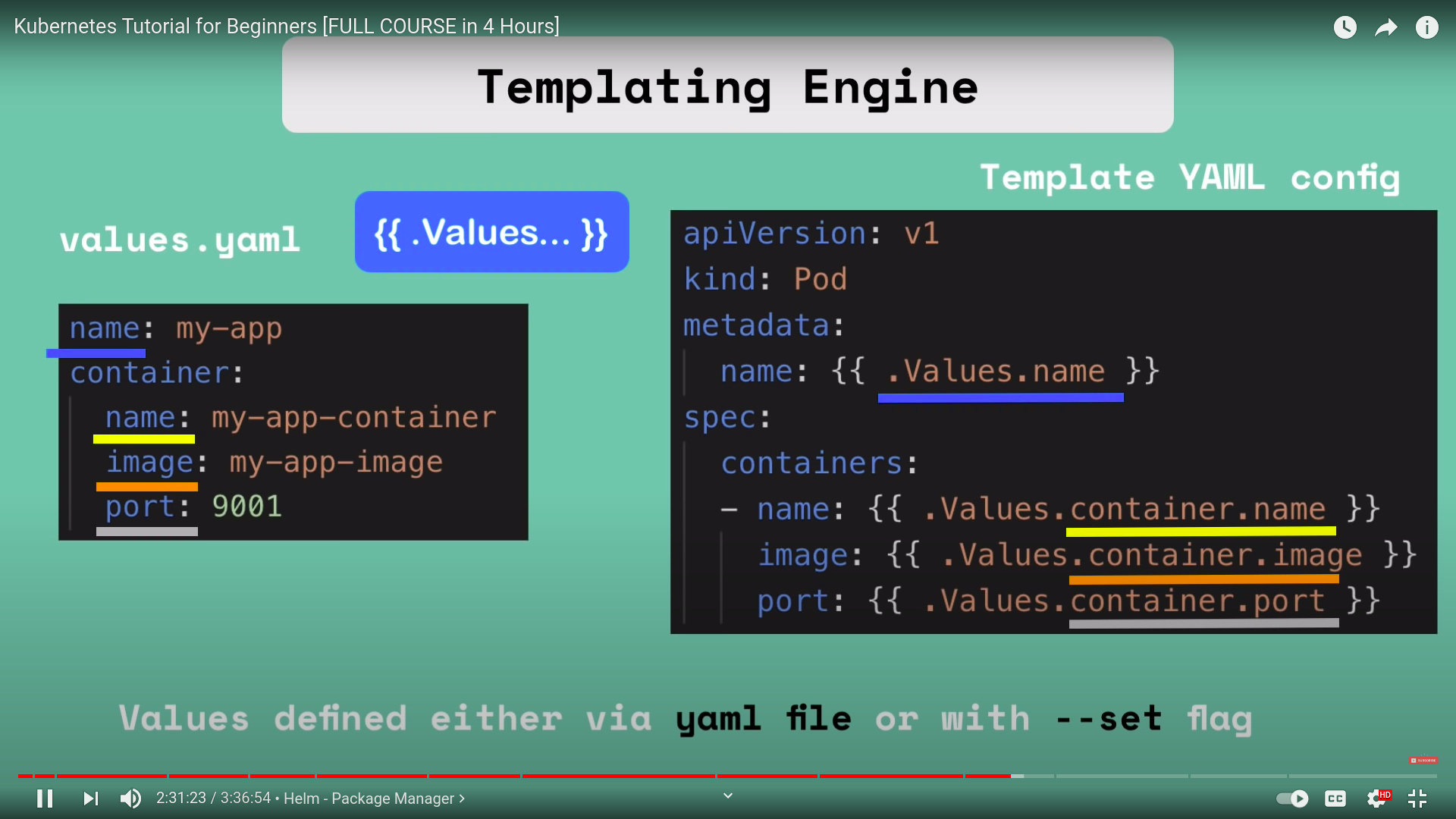
deploying same app across diff envs
helm chart structure
- values.yaml has the default values and can be overriden

- release management
- tiller
- downside security
- tiller
k8s Volumes
- persistent volume
- persistent volume claim
- storage class
- we need a storage that doesn't depend on pod lifecycle
- storage must be available on all nodes bec, we don't know on which node it will start
- storage needs to survive even if the cluster crash
- cluster resource
- created via yaml file
- we need physical storage
- what type of storage you need ?
- you have to manage and create them by yourself
- k8s gives you an interface for persistant data and you have to provide the actual storage

- PV are not namespaced, available to all namespaces
local vs remote volume
- each has its own use case
- local violates 2 and 3 requirement for data persistance:
- being tied to 1 specific node
- surviving in cluster crashes
- for DB persistance use remote
who creates and when ?
- it has to be there before the pod that depends on it created
- K8S admin creates it
- k8s users -devs and devops- has to claims the storage using
persistanceVolumeClaim
- claims must be in the same namespace
- volume is mounted to the pod then it can be mounted into the container
- you can create configMap or secret and mount it as volume
storage class
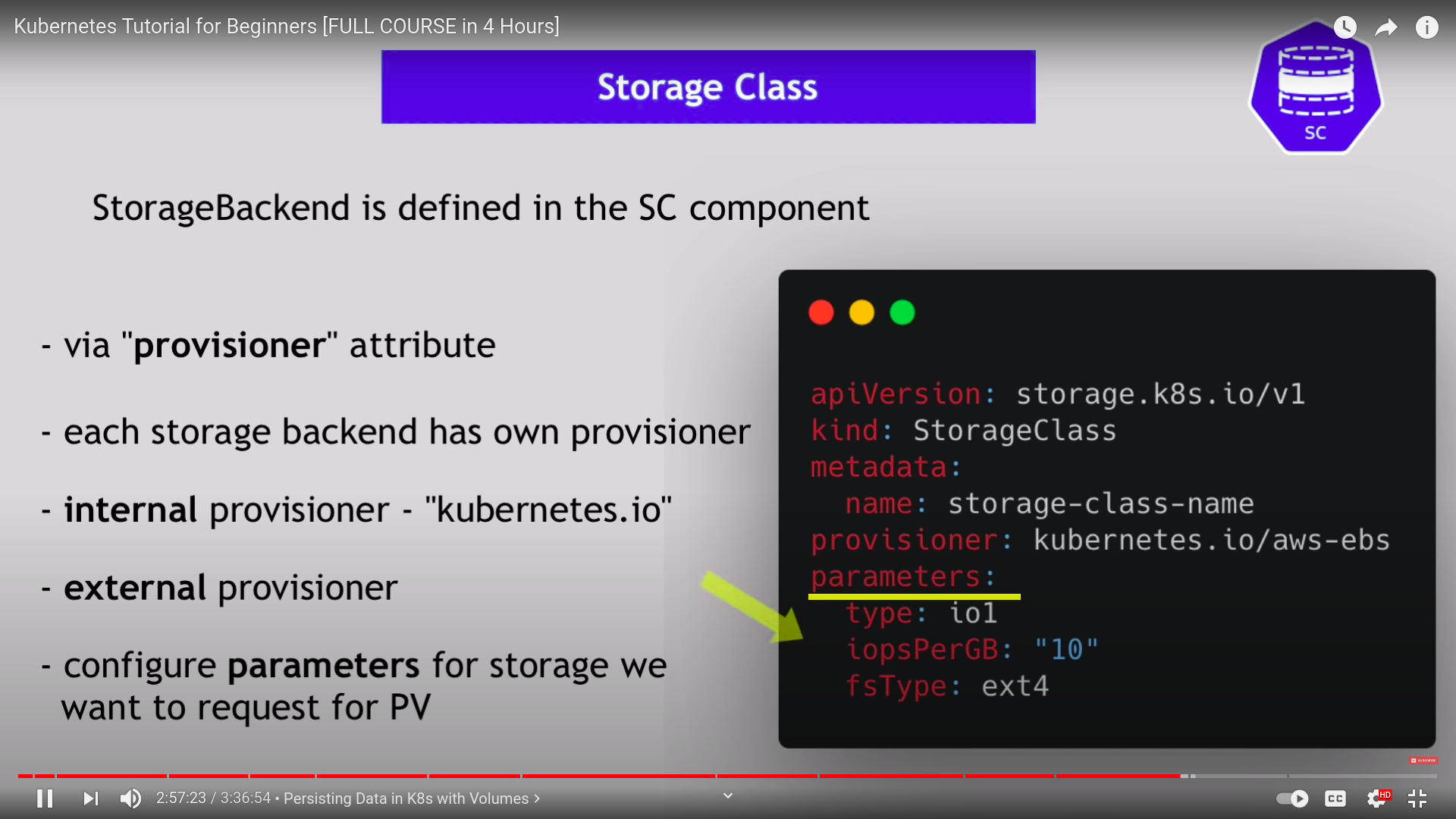
statefulSet for stateful applications
- scalling
- one master and other slaves
- have access to the same data but not the same persistant volumes

k8s services
what and why ?
- each pod has its own ip address
- pods are ephermal- are destroyed frequently
- service
- is stable
- loadbalancing
- loose coupling
- within and outside cluster
clusterIP services
- default type
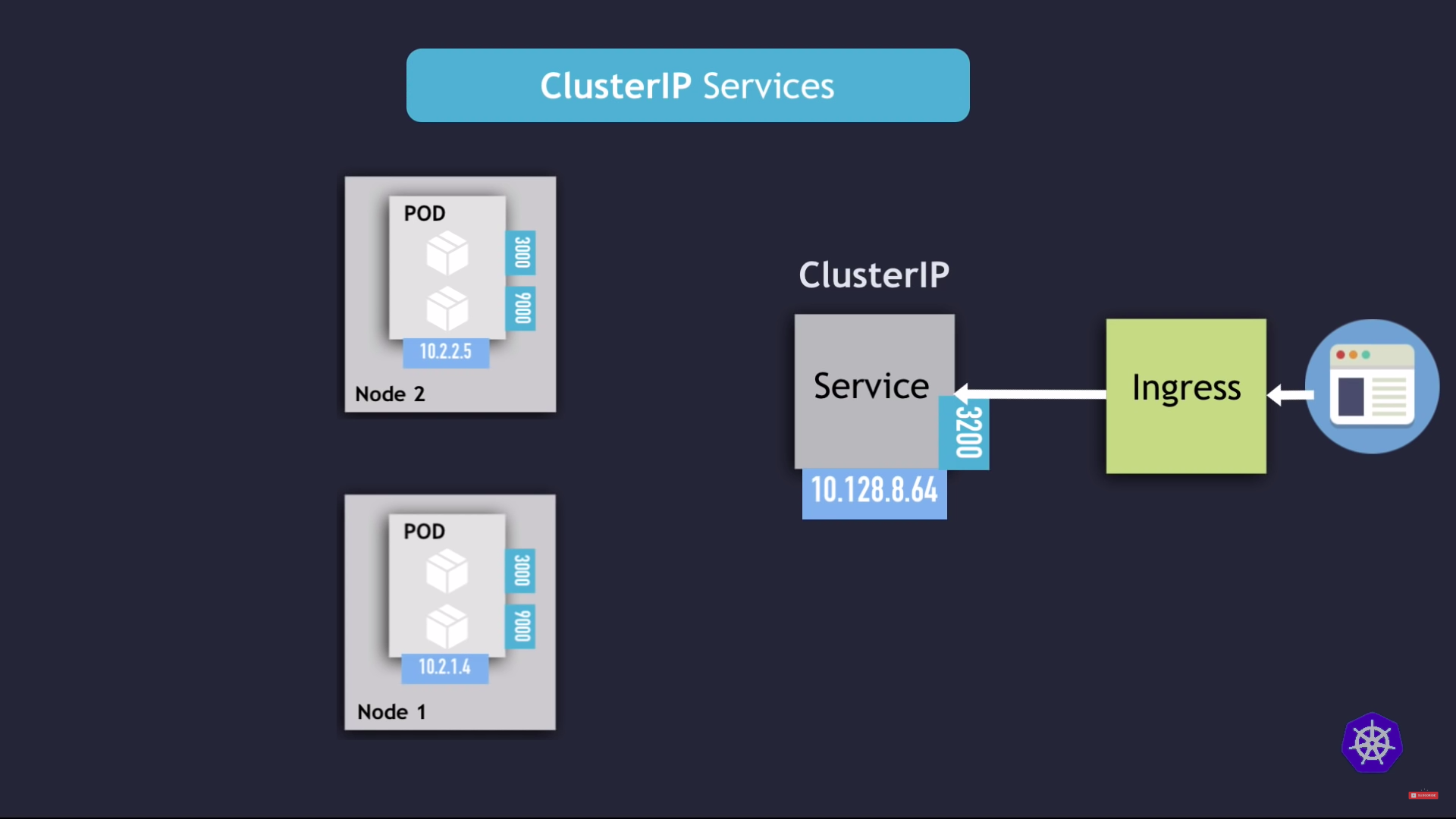
service communication : selector
- which pods to forward the request to ?
- using selectors
- key value pairs
- labels of pods
- pods with multiple ports?
- with
targetPortattribute
- with
- k8s creates
endpoint object- same name as service
- keeps track of the members/endpoints of the service
- service port is arbitary
- target port must match the port, the container listening to
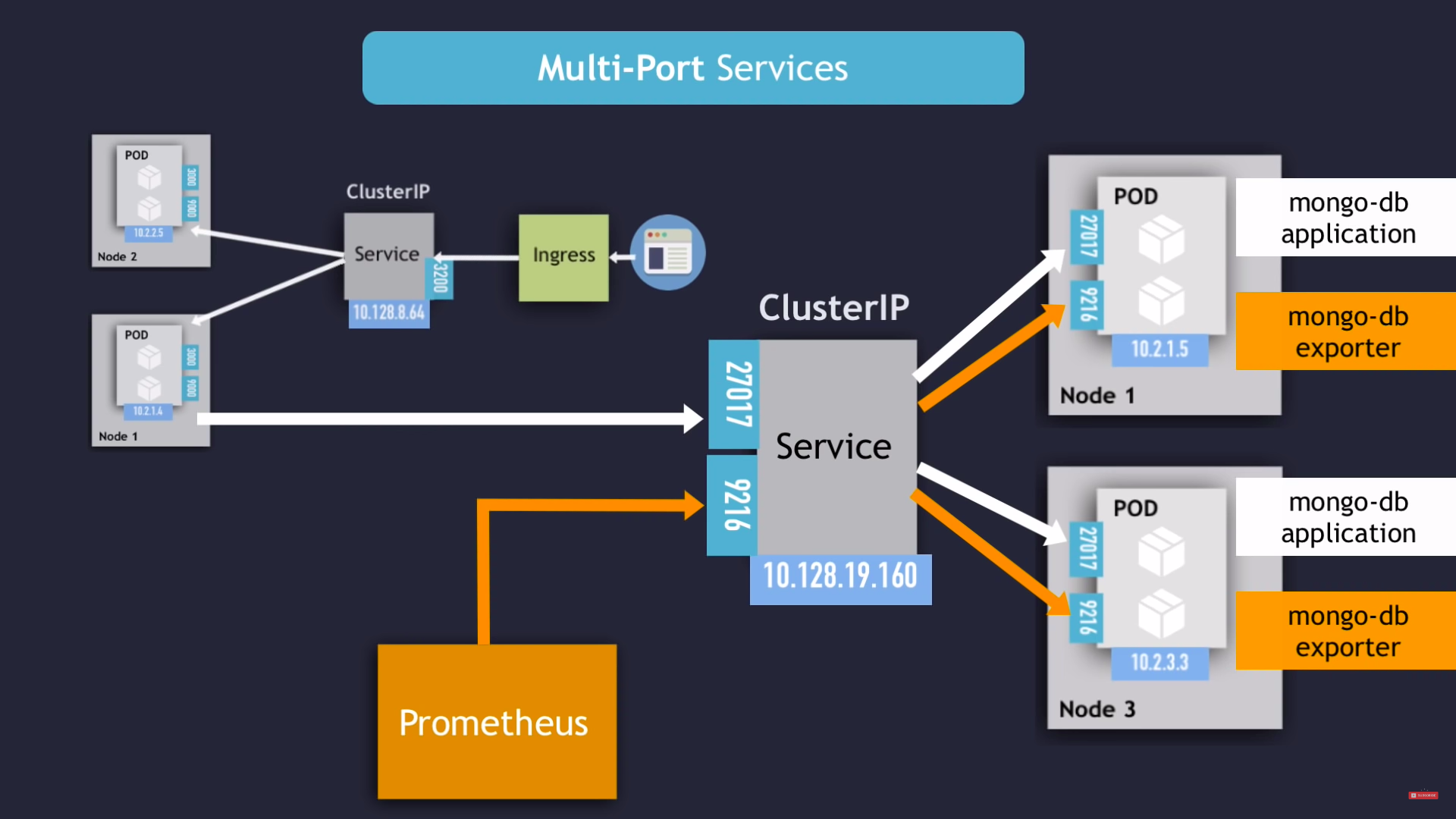
multiple port services
- in case you have 2 things to connect to in the same pod and with different ports
- you have to name the ports
headless service
- client want to communicate with specific pod
- pods want to communicate with specific pod
- use cases
- stateful apps
- pods are not identical
- we have 2 options
- API call to k8s api server?
- inefficient
- make app too tied to k8s api
- DNS look up
- DNS lookup for service ip - returns single ip of ClusterIP
- set
ClusterIptonone- returns the Pod Ip address instead
‼️when we deploy stateful app we have theclusterIpwhich do the load balancing and reach any of the pods in case we don't need a specific pod but when we need to take to a specific pod in case of writing for example we want to write to the master node only we haveheadless service - API call to k8s api server?
NodePort service
- when we need to use ip from outside the cluster
clusterIpis automatically created
load Balancer service
clusterIpandNodePortare automatically created by k8s, in which external loadbalancer of cloud will route the traffic to
- extenstion of NodePort which is extension of Cluster IP